一、项目网址
Github仓库:https://github.com/rasbt/LLMs-from-scratch
二、作者介绍
作者官网:https://sebastianraschka.com
Sebastian Raschka 是一名机器学习和人工智能研究员,曾在威斯康星大学麦迪逊分校担任统计学助理教授,专门研究深度学习和机器学习。他致力于使关于 AI 和深度学习相关的内容更简单易懂。除了编写代码,Sebastian 还喜欢写作,他撰写了畅销书《Python Machine Learning》(《Python 机器学习》)和《Machine Learning with PyTorch and ScikitLearn》。
Sebastian Raschka博士具有科研和企业的双重经验,虽然他并不是目前最热门的AI专家,但是Sebastian Raschka热衷且擅长于科普和教育,所以对于大语言模型初学者来说,Sebastian Raschka博士能够提供很好的入门帮助。

三、项目介绍
该项目是Sebastian Raschka博士《Bulid A Large Language Model》的官方配套代码库。
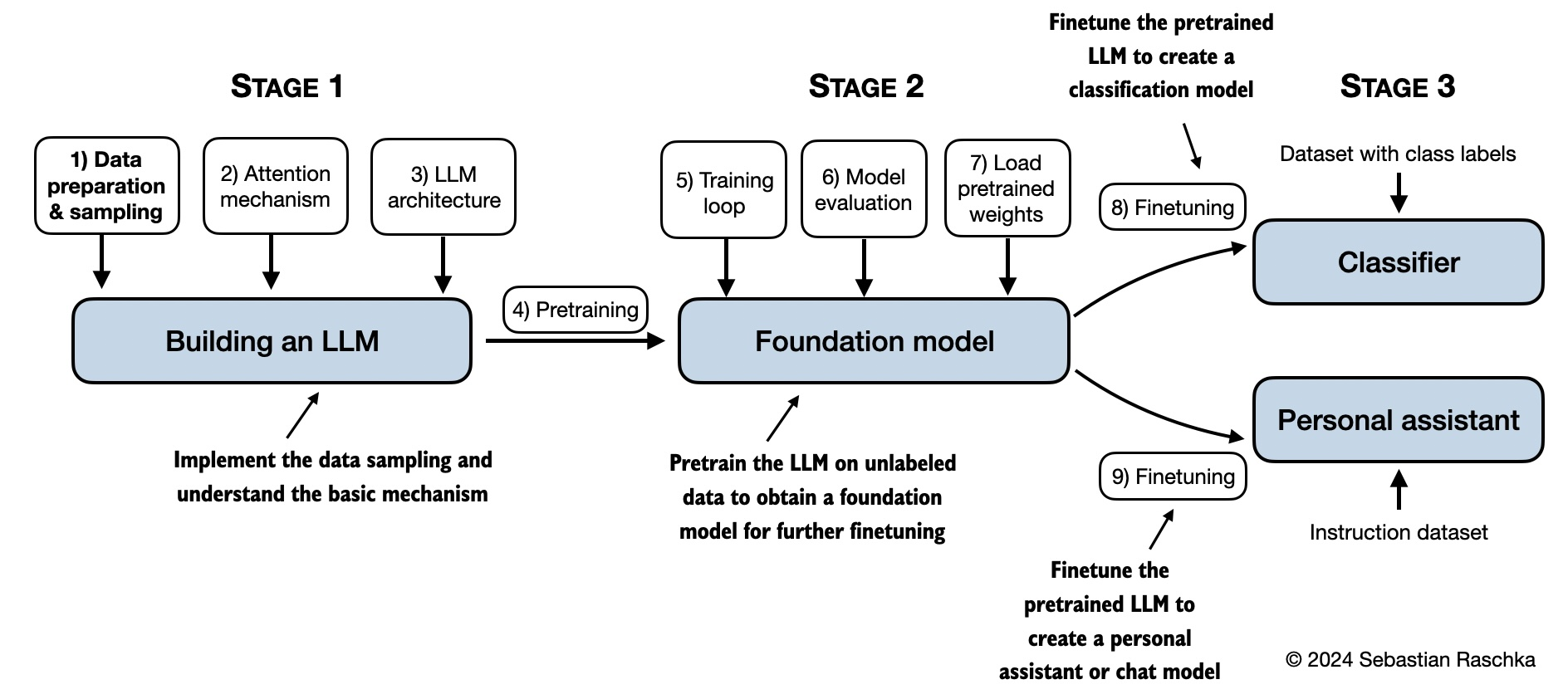
在《Bulid A Large Language Model》中您将通过从头开始逐步编写大语言模型 LLM 来学习和理解它们如何从内到外工作。Sebastian Raschka博士将指导您创建自己的 LLM,用清晰的文本、图表和示例解释每个阶段。描述用于训练和开发您自己的小型但功能强大的模型反映了用于创建大规模基础模型(例如 ChatGPT 背后的模型)的方法。此外,书中还包括用于加载大型预训练模型的权重以进行微调的代码。

该项目包含了与书籍每一章节对应的Jupyter交互笔记,笔记中包含了书中的大部分内容,还包含用于开发、预训练和微调类似 GPT 的 LLM 的代码。Jupyter交互笔记经过简单的配置即可在Jupyter环境或者VS code环境中阅读和交互运行。因此即使你没有购买原版书籍,也可以一步一步完成 LLM的构建。整个项目基于Python语言,对于有Python基础的朋友能够较为容易理解项目中的代码。
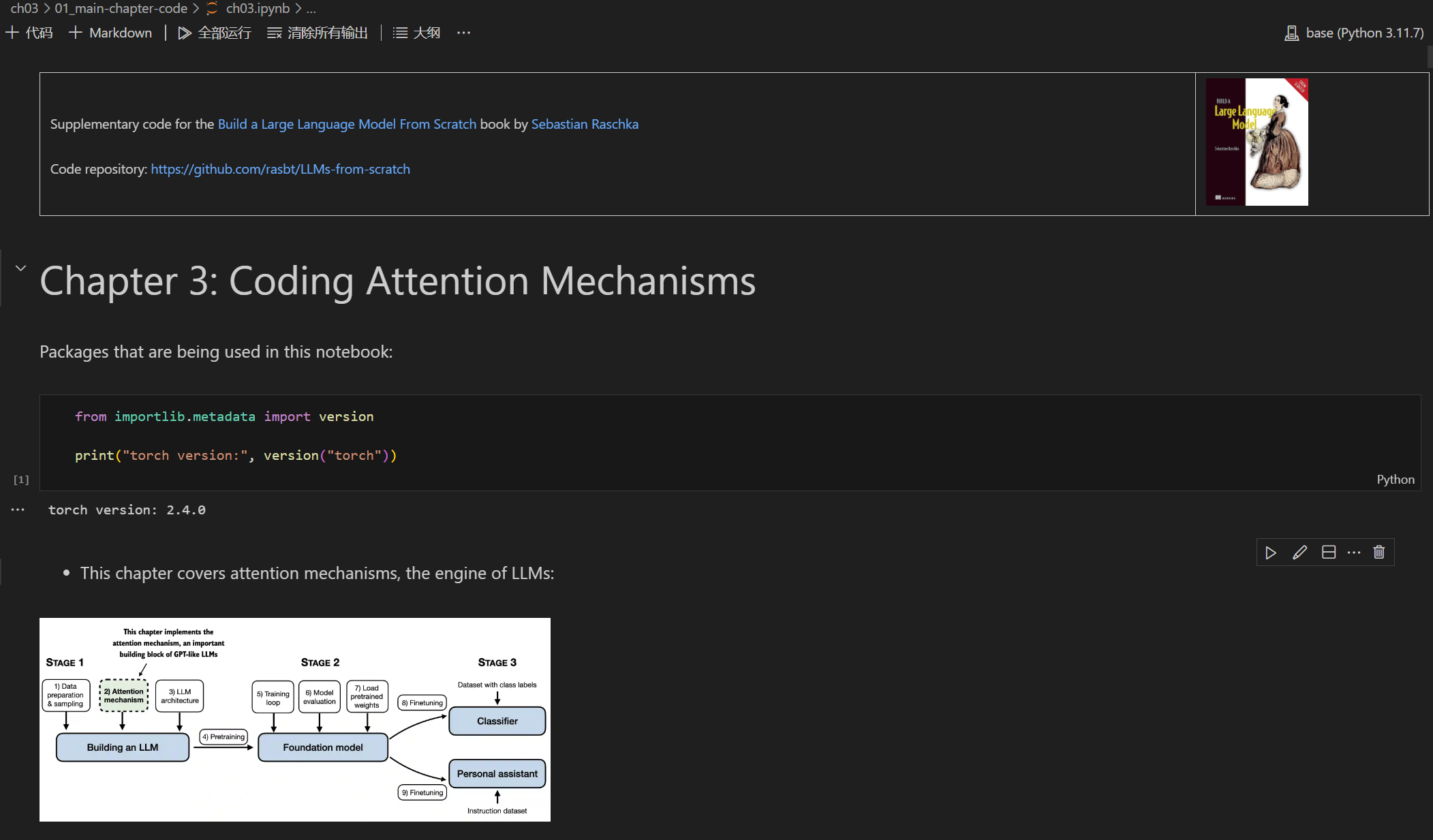
截至本文发表,该项目在Github已经获得了41.1k星,人气非常高。项目的主要内容如下所示,希望能为您入门LLM带来帮助。
| 章节 | 内容 |
|---|---|
| 序言 | 安装使用指导 |
| 第 1 章 | 理解大型语言模型 |
| 第 2 章 | 使用文本数据 |
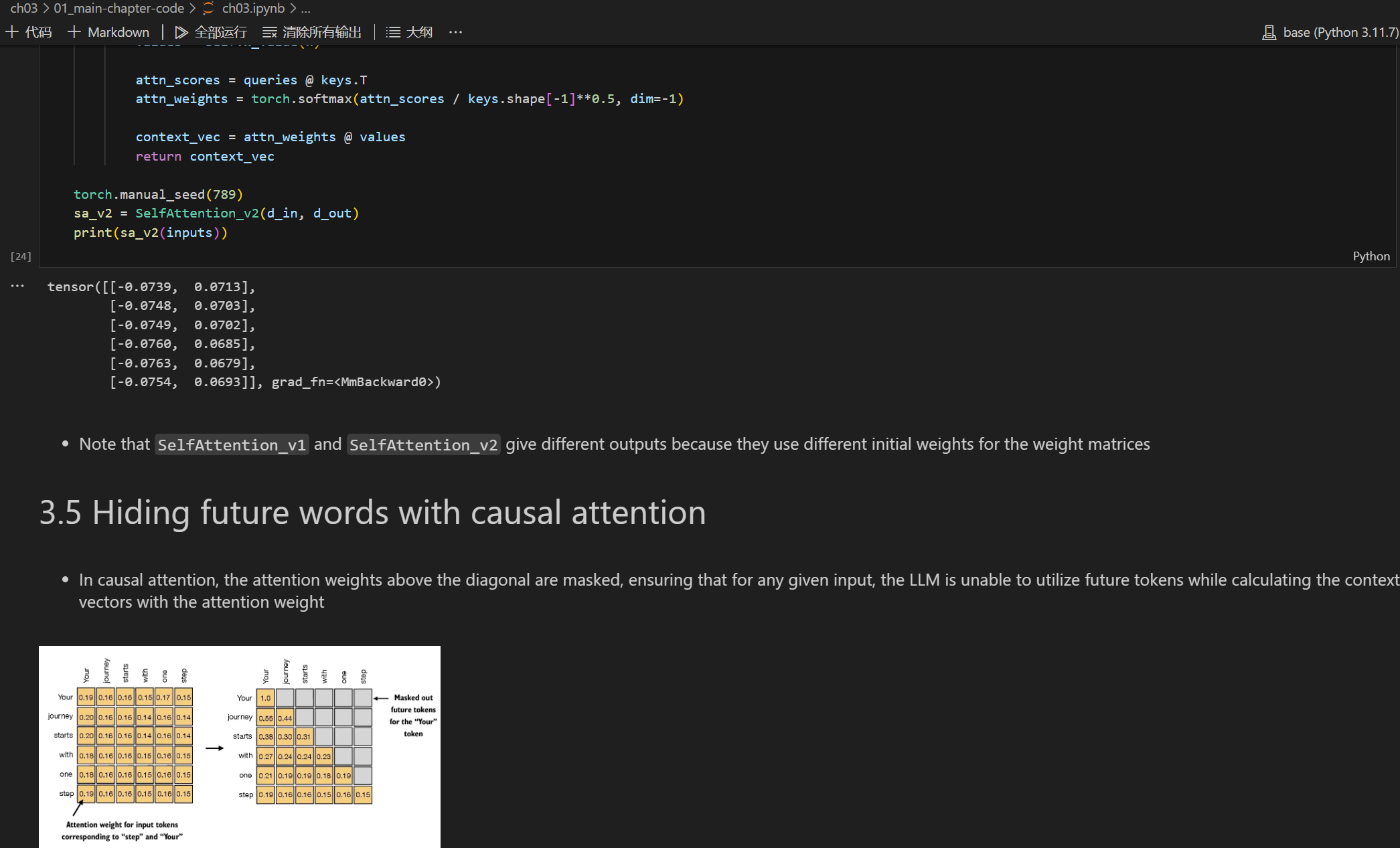
| 第 3 章 | 编码注意力机制 |
| 第 4 章 | 从头开始实施 GPT 模型 |
| 第 5 章 | 未标记数据的预训练 |
| 第 6 章 | 用于文本分类的微调 |
| 第 7 章 | 用于遵循指令的微调 |
| 附录 A | PyTorch 简介 |
| 附录 B | 参考资料和进一步阅读 |
| 附录 C | 练习题答案 |
| 附录 D | 为训练循环增添亮点 |
| 附录 E | 使用 LoRA 进行参数高效微调 |
友情提醒:
本官方内容包含对第三方产品或服务的介绍,仅供参考。请您在做出选择时进行充分考量,本站不对任何第三方产品或服务的使用后果承担责任。
- 除非另有明确标注,本站内容的版权均归属于原始发布者。未经发布者和本站明确授权,任何个人或组织均不得复制、盗用、采集或以其他任何方式将本站内容发布至其他媒介或平台。
- 若本站内容侵犯了您的合法权益,请联系我们进行处理。
- 对于非本站官方发布的内容,本站无法对其具体内容承担责任。请用户务必自行仔细甄别信息的真实性、准确性和完整性。